Publications
Connecting Symbolic Statutory Reasoning with Legal Information Extraction [paper] [resources]
Nils Holzenberger and Benjamin Van Durme
Proceedings of the 2023 Natural Legal Language Processing (NLLP) Workshop, 7 December 2023, Singapore
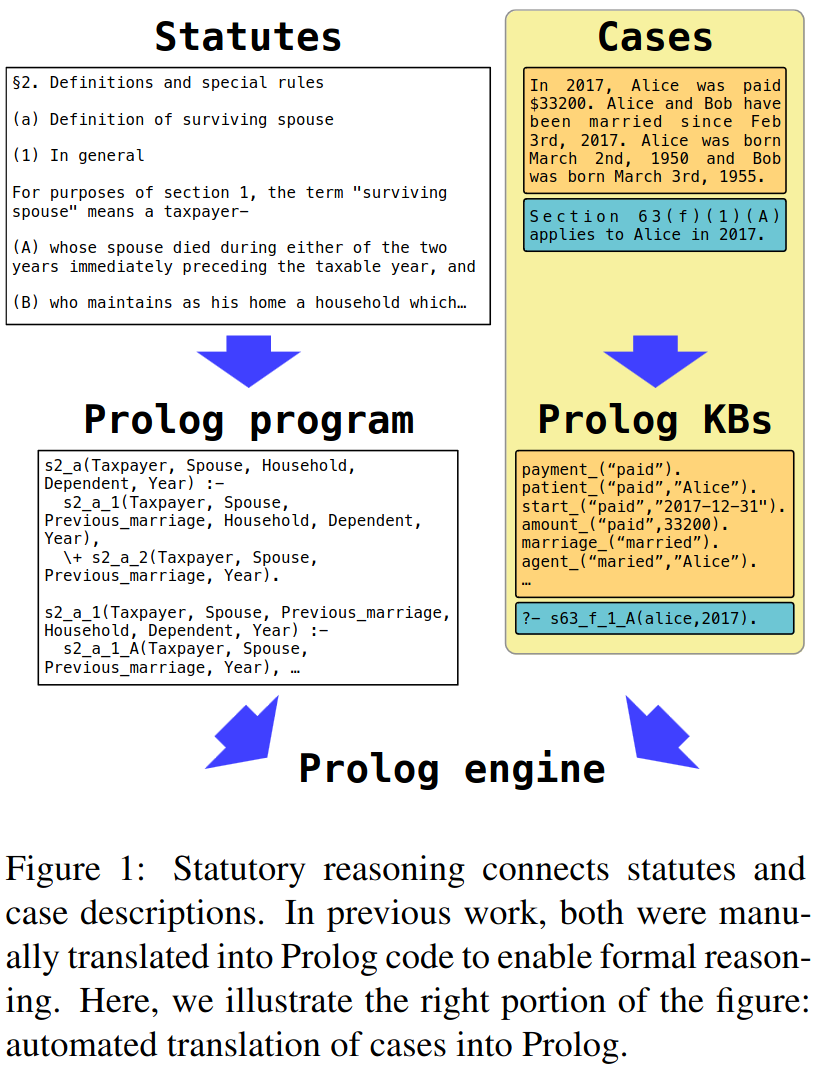 Statutory reasoning is the task of determining whether a given law – a part of a statute – applies to a given legal case. Previous work has shown that structured, logical representations of laws and cases can be leveraged to solve statutory reasoning, including on the StAtutory Reasoning Assessment dataset (SARA), but rely on costly human translation into structured representations. Here, we investigate a form of legal information extraction atop the SARA cases, illustrating how the task can be done with high performance. Further, we show how the performance of downstream symbolic reasoning directly correlates with the quality of the information extraction.
Statutory reasoning is the task of determining whether a given law – a part of a statute – applies to a given legal case. Previous work has shown that structured, logical representations of laws and cases can be leveraged to solve statutory reasoning, including on the StAtutory Reasoning Assessment dataset (SARA), but rely on costly human translation into structured representations. Here, we investigate a form of legal information extraction atop the SARA cases, illustrating how the task can be done with high performance. Further, we show how the performance of downstream symbolic reasoning directly correlates with the quality of the information extraction.
OpenAI Cribbed Our Tax Example, But Can GPT-4 Really Do Tax? [paper]
Andrew Blair-Stanek, Nils Holzenberger and Benjamin Van Durme
Tax Notes Federal, August 14, 2023
Can GPT-3 Perform Statutory Reasoning? [paper]
Andrew Blair-Stanek, Nils Holzenberger and Benjamin Van Durme
ICAIL, 2023
 Statutory reasoning is the task of reasoning with facts and statutes, which are rules written in natural language by a legislature. It is a basic legal skill. In this paper we explore the capabilities of the most capable GPT-3 model, text-davinci-003, on an established statutory-reasoning dataset called SARA. We consider a variety of approaches, including dynamic few-shot prompting, chain-ofthought prompting, and zero-shot prompting. While we achieve results with GPT-3 that are better than the previous best published results, we also identify several types of clear errors it makes. We investigate why these errors happen. We discover that GPT-3 has imperfect prior knowledge of the actual U.S. statutes on which SARA is based. More importantly, we create simple synthetic statutes, which GPT-3 is guaranteed not to have seen during training. We find GPT-3 performs poorly at answering straightforward questions about these simple synthetic statutes.
Statutory reasoning is the task of reasoning with facts and statutes, which are rules written in natural language by a legislature. It is a basic legal skill. In this paper we explore the capabilities of the most capable GPT-3 model, text-davinci-003, on an established statutory-reasoning dataset called SARA. We consider a variety of approaches, including dynamic few-shot prompting, chain-ofthought prompting, and zero-shot prompting. While we achieve results with GPT-3 that are better than the previous best published results, we also identify several types of clear errors it makes. We investigate why these errors happen. We discover that GPT-3 has imperfect prior knowledge of the actual U.S. statutes on which SARA is based. More importantly, we create simple synthetic statutes, which GPT-3 is guaranteed not to have seen during training. We find GPT-3 performs poorly at answering straightforward questions about these simple synthetic statutes.
Shelter Check: Proactively Finding Tax Minimization Strategies via AI [paper]
Andrew Blair-Stanek, Nils Holzenberger and Benjamin Van Durme
Tax Notes Federal, December 12, 2022
Improved Induction of Narrative Chains via Cross-Document Relations [paper] [resources]
Andrew Blair-Stanek and Benjamin Van Durme
*Sem, 2022
Factoring Statutory Reasoning as Language Understanding Challenges [paper] [resources]
Nils Holzenberger and Benjamin Van Durme
ACL, 2021
 Statutory reasoning is the task of determining whether a legal statute, stated in natural language, applies to the text description of a case. Prior work introduced a resource that approached statutory reasoning as a monolithic textual entailment problem, with neural baselines performing nearly at-chance. To address this challenge, we decompose statutory reasoning into four types of language-understanding challenge problems, through the introduction of concepts and structure found in Prolog programs. Augmenting an existing benchmark, we provide annotations for the four tasks, and baselines for three of them. Models for statutory reasoning are shown to benefit from the additional structure, improving on prior baselines. Further, the decomposition into subtasks facilitates finer-grained model diagnostics and clearer incremental progress.
Statutory reasoning is the task of determining whether a legal statute, stated in natural language, applies to the text description of a case. Prior work introduced a resource that approached statutory reasoning as a monolithic textual entailment problem, with neural baselines performing nearly at-chance. To address this challenge, we decompose statutory reasoning into four types of language-understanding challenge problems, through the introduction of concepts and structure found in Prolog programs. Augmenting an existing benchmark, we provide annotations for the four tasks, and baselines for three of them. Models for statutory reasoning are shown to benefit from the additional structure, improving on prior baselines. Further, the decomposition into subtasks facilitates finer-grained model diagnostics and clearer incremental progress.
AI for Tax Analogies and Code Renumbering [paper] [resources]
Andrew Blair-Stanek and Benjamin Van Durme
Tax Notes Federal, March 29, 2021
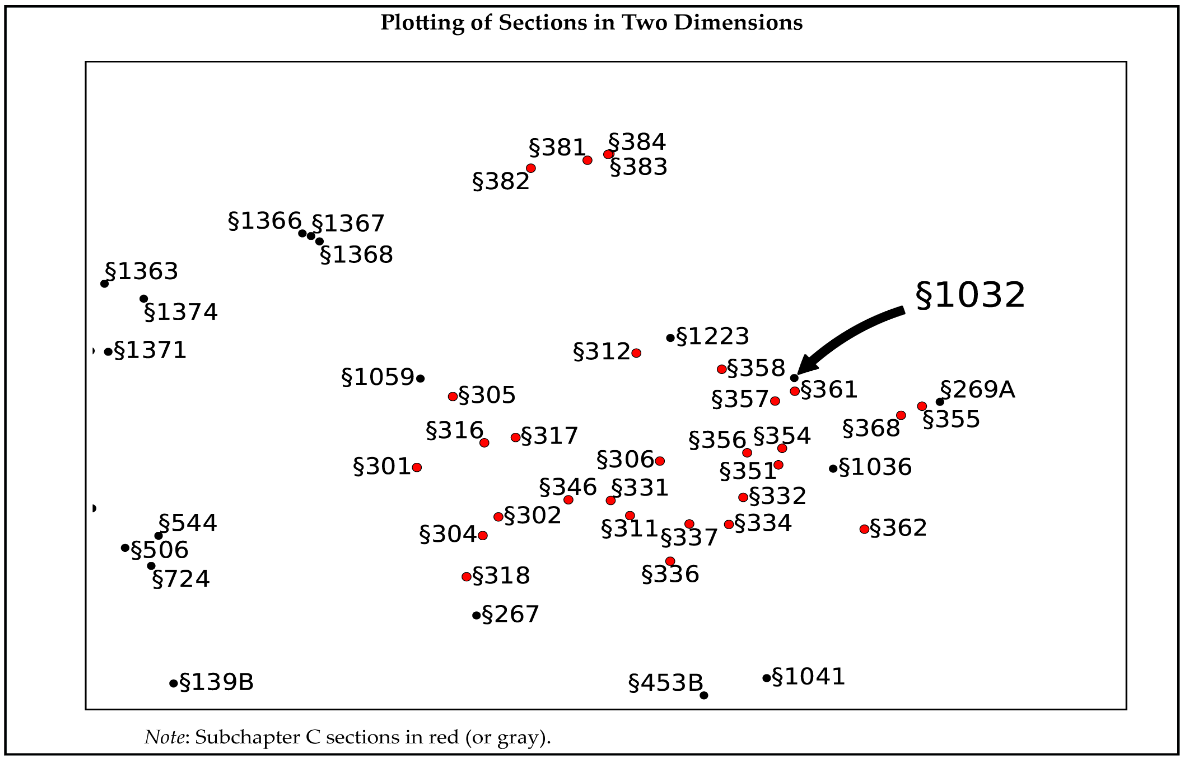 We present an artificial intelligence tool that can complete analogies in tax law and provide evidence-based guidance on how Congress can renumber IRC sections in future tax reform efforts.
We present an artificial intelligence tool that can complete analogies in tax law and provide evidence-based guidance on how Congress can renumber IRC sections in future tax reform efforts.
A Dataset for Statutory Reasoning in Tax Law Entailment and Question Answering [paper] [resources] [featured on AI2's NLP Highlights podcast]
Nils Holzenberger, Andrew Blair-Stanek and Benjamin Van Durme
Proceedings of the 2020 Natural Legal Language Processing (NLLP) Workshop, 24 August 2020, San Diego, US
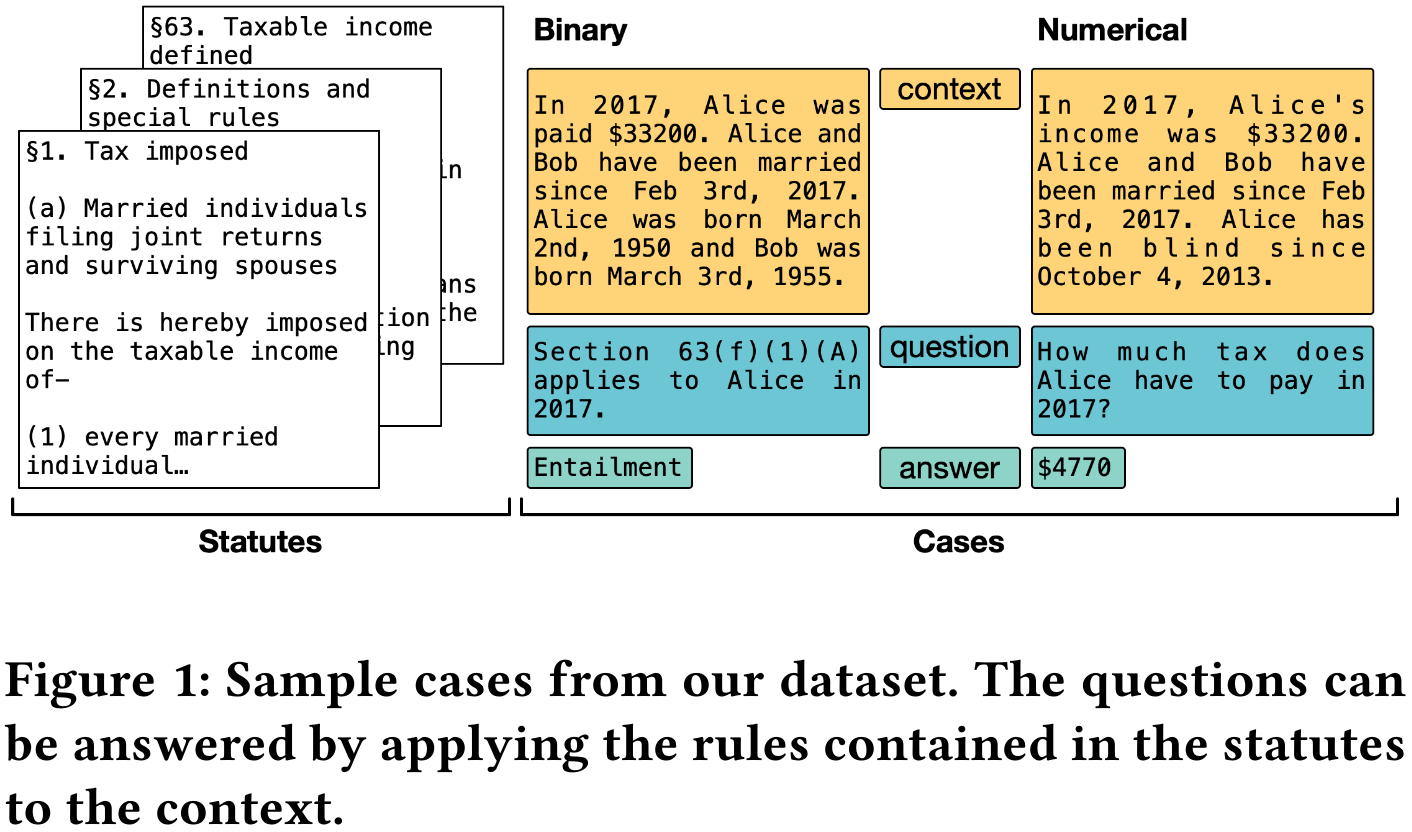 Legislation can be viewed as a body of prescriptive rules expressed in natural language. The application of legislation to facts of a case we refer to as statutory reasoning, where those facts are also expressed in natural language. Computational statutory reasoning is distinct from most existing work in machine reading, in that much of the information needed for deciding a case is declared exactly once (a law), while the information needed in much of machine reading tends to be learned through distributional language statistics. To investigate the performance of natural language understanding approaches on statutory reasoning, we introduce a dataset, together with a legal-domain text corpus. Straightforward application of machine reading models exhibits low out-of-the-box performance on our questions, whether or not they have been fine-tuned to the legal domain. We contrast this with a hand-constructed Prolog-based system, designed to fully solve the task. These experiments support a discussion of the challenges facing statutory reasoning moving forward, which we argue is an interesting real-world task that can motivate the development of models able to utilize prescriptive rules specified in natural language.
Legislation can be viewed as a body of prescriptive rules expressed in natural language. The application of legislation to facts of a case we refer to as statutory reasoning, where those facts are also expressed in natural language. Computational statutory reasoning is distinct from most existing work in machine reading, in that much of the information needed for deciding a case is declared exactly once (a law), while the information needed in much of machine reading tends to be learned through distributional language statistics. To investigate the performance of natural language understanding approaches on statutory reasoning, we introduce a dataset, together with a legal-domain text corpus. Straightforward application of machine reading models exhibits low out-of-the-box performance on our questions, whether or not they have been fine-tuned to the legal domain. We contrast this with a hand-constructed Prolog-based system, designed to fully solve the task. These experiments support a discussion of the challenges facing statutory reasoning moving forward, which we argue is an interesting real-world task that can motivate the development of models able to utilize prescriptive rules specified in natural language.


