These projects explore compressed representations ("nuggets") of meaning.
IWCS 2017: https://aclanthology.org/W17-6936/
Abstract: We introduce the notion of a multi-vector sentence representation based on a “one vector per proposition” philosophy, which we term skip-prop vectors. By representing each predicate-argument structure in a complex sentence as an individual vector, skip-prop is (1) a response to empirical evidence that single-vector sentence representations degrade with sentence length, and (2) a representation that maintains a semantically useful level of granularity. We demonstrate the feasibility of training skip-prop vectors, introducing a method adapted from skip-thought vectors, and compare skip-prop with “one vector per sentence” and “one vector per token” approaches.

ICML 2023: https://arxiv.org/abs/2310.01732
Abstract: Embedding text sequences is a widespread requirement in modern language understanding. Existing approaches focus largely on constantsize representations. This is problematic, as the amount of information contained in text can vary. We propose a solution called NUGGET , which encodes language into a representation based on a dynamically selected subset of input tokens. These nuggets are learned through tasks like autoencoding and machine translation, and intuitively segment language into meaningful units. We demonstrate NUGGET outperforms related approaches in tasks involving semantic comparison. Finally, we illustrate these compact units allow for expanding the contextual window of a language model (LM), suggesting new future LMs that can condition on larger amounts of content.
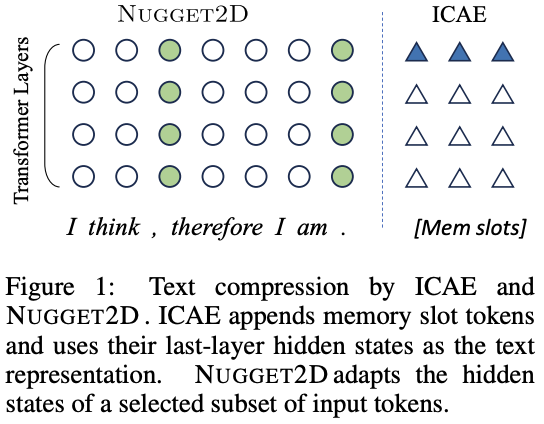
arXiv 2023: https://arxiv.org/abs/2310.02409
Tweet on Nugget and Nugget2D, Oct 10, 2023
Abstract: Standard Transformer-based language models (LMs) scale poorly to long contexts. We propose a solution based on dynamic contextual compression, which extends the Nugget approach of Qin & Van Durme (2023) from BERT-like frameworks to decoder-only LMs. Our method models history as compressed "nuggets" which are trained to allow for reconstruction, and it can be initialized with off-the-shelf models such as LLaMA. We demonstrate through experiments in language modeling, question answering, and summarization that Nugget2D retains capabilities in these tasks, while drastically reducing the overhead during decoding in terms of time and space. For example, in the experiments of autoencoding, Nugget2D can shrink context at a 20x compression ratio with a BLEU score of 98% for reconstruction, achieving nearly lossless encoding.

arXiv 2023: https://arxiv.org/abs/2311.08620
GitHub: https://github.com/JHU-CLSP/toucan
Abstract: Character-level language models obviate the need for separately trained tokenizers, but efficiency suffers from longer sequence lengths. Learning to combine character representations into tokens has made training these models more efficient, but they still require decoding characters individually. We propose Toucan, an augmentation to character-level models to make them “token-aware”. Comparing our method to prior work, we demonstrate significant speed-ups in character generation without a loss in language modeling performance. We then explore differences between our learned dynamic tokenization of character sequences with popular fixed vocabulary solutions such as Byte-Pair Encoding and WordPiece, finding our approach leads to a greater amount of longer sequences tokenized as single items.